
Você viu o hype e quer saber se isso funciona no mundo real. Boa. O jeito certo de testar é simples, e rápido, se você fizer com checklist, métricas e um caso de uso fechado. PersonaPlex tem suporte a avaliação offline via script, e também opções para reduzir demanda de VRAM com --cpu-offload, além de ser possível fazer avaliação offline em CPU puro com PyTorch CPU.
A seguir, um guia prático para você testar sem virar refém de configuração infinita.
O que você precisa, máquina, áudio, ambiente
1) Máquina, o mínimo para não travar
Seu objetivo no primeiro teste não é “rodar perfeito”, é validar comportamento, latência e estabilidade.
Cenário A, teste real-time com GPU
- Ideal para avaliar conversa em tempo real, porque reduz latência e engasgos.
- Se faltar memória na GPU, o próprio projeto menciona
--cpu-offloadcomo alternativa.
Cenário B, teste offline
- Perfeito para começar sem stress. Você usa um arquivo WAV como entrada e o script gera um WAV de saída com a mesma duração, ótimo para medir qualidade de fala e consistência.
Cenário C, CPU puro
- Útil para validar o pipeline e a qualidade geral, mas não espere “tempo real”.
- A recomendação do próprio repositório é instalar PyTorch CPU para avaliação offline em CPU.
Expectativa realista
- Se a sua meta é “conversar natural e rápido”, GPU faz diferença.
- Se sua meta é “entender se o modelo serve para o meu produto”, offline resolve o primeiro ciclo.
2) Áudio, o que dá menos dor de cabeça
Para não confundir “problema do modelo” com “problema do áudio”, padronize isso:
Checklist de áudio:
- Use WAV com voz clara, sem música e sem ruído.
- Grave em ambiente silencioso, sem eco.
- Faça 3 amostras curtas, 10 a 20 segundos cada, em vez de um áudio longo.
3) Ambiente de teste, seja clínico
Monte um ambiente de teste que você consegue repetir.
Checklist de ambiente:
- Sempre o mesmo microfone e o mesmo local.
- Sem ventilador, TV, rua, reverberação.
- Sem multitarefa pesada no PC durante o teste.
Se você não controlar isso, você vai “achar problema” onde não existe.
O que medir, latência, estabilidade, qualidade de fala
Se você não medir 3 coisas, você só vai sair com opinião. O mínimo que presta é:
1) Latência percebida
Você quer saber quanto tempo passa entre você falar e o modelo reagir.
Métrica simples:
- Cronometre 10 respostas.
- Anote o tempo médio e o pior caso.
Classificação prática:
- Abaixo de 1s, excelente para conversa.
- 1 a 2s, aceitável para muitos casos.
- Acima de 2s, vira atendimento travado.
Se você estiver no modo offline, a latência real-time não vale, mas você ainda consegue medir consistência de saída e fluidez.
2) Estabilidade
Aqui você está caçando travamento, engasgo, repetição e “derrapada” de conversa.
Checklist de estabilidade:
- Responde sem travar por 5 minutos?
- O áudio sai contínuo ou sai picotado?
- Ele mantém o contexto por 3 a 5 turnos?
- Ele começa a repetir padrões?
Se tiver instabilidade por falta de VRAM, use --cpu-offload para conseguir rodar e testar comportamento.
3) Qualidade de fala e naturalidade
Essa é a parte que vende “full-duplex”, mas você precisa medir com critérios.
Rubrica simples, nota de 0 a 2 em cada item:
- Clareza, dá para entender sem esforço.
- Naturalidade, parece conversa, não “voz lendo”.
- Turn-taking, ele não atropela demais, nem fica morto.
- Respostas curtas, ele não vira palestrinha.
Faça isso em 3 cenários, perguntas objetivas, perguntas emocionais, perguntas com interrupção.
Um detalhe crítico sobre idioma
O README do modelo descreve o caso de uso como gerar resposta em inglês para entrada em inglês. Então, para um teste honesto, valide primeiro em inglês, e só depois você explora português.
Se você testar direto em português e ficar ruim, você não vai saber se o problema é do modelo ou do idioma.
Como validar caso de uso sem virar projeto infinito
Você vai cair na armadilha clássica, “vamos integrar com tudo”, “vamos testar 50 coisas”. Não faça isso.
Use este método de 60 minutos.
Passo 1, defina 1 caso de uso fechado
Escolha 1 só, e trave o escopo.
Exemplos bons:
- Recepção, agendamento simples.
- Qualificação de lead, 5 perguntas.
- FAQ de produto, 10 perguntas.
Exemplos ruins:
- “Assistente geral para tudo.”
- “Atendimento completo com decisões complexas.”
Passo 2, crie um roteiro de teste com 15 prompts
Divida em 3 blocos, cada um com 5 perguntas:
- Bloco A, perguntas diretas.
- Bloco B, perguntas com ambiguidade.
- Bloco C, interrupção e correção, “não, era outra coisa”.
Você vai usar sempre o mesmo roteiro. Isso dá comparabilidade.
Passo 3, rode em 2 modos
- Offline para validar qualidade e consistência. O repositório descreve script offline com WAV de entrada e WAV de saída.
- Real-time para validar latência e comportamento de conversa, se você tiver GPU.
Passo 4, saia com uma decisão binária
No final, você não precisa “amar” o modelo. Você precisa decidir:
- Serve para o meu caso agora, sim ou não.
- O que falta, hardware, idioma, estabilidade, custo.
Passo 5, produza um “relatório de 1 página”
Sem relatório de 1 página, você se perde.
Modelo de relatório:
- Caso de uso testado.
- Ambiente, GPU ou CPU, offline ou real-time.
- Latência média, pior caso.
- Estabilidade, travou, sim ou não.
- Nota de naturalidade, 0 a 8.
- Decisão e próximo passo.
Quando não vale a pena usar agora
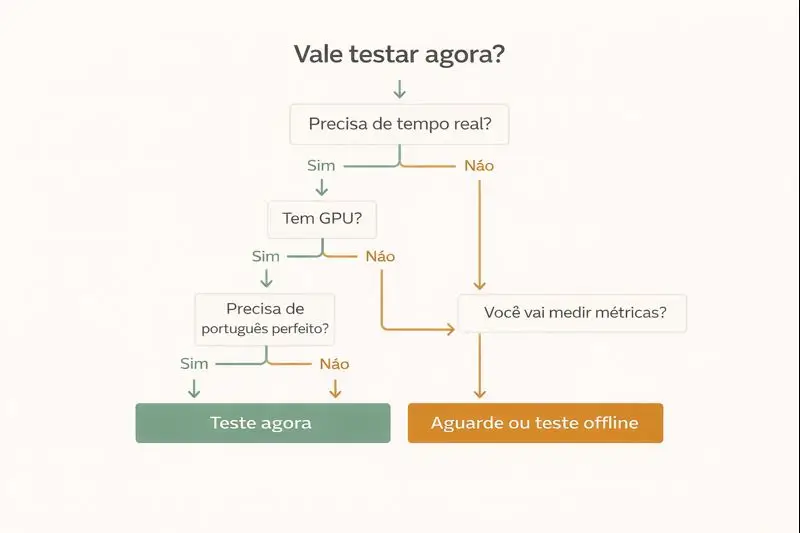
Vou ser direto. Não vale a pena se você está em qualquer um desses cenários.
- Você precisa de português perfeito desde o dia 1
O próprio caso de uso descrito está centrado em inglês. Se seu produto é Brasil e você não aceita degradação, você vai sofrer. - Você não tem como medir e iterar
Se você não vai coletar latência, estabilidade e qualidade, você vai virar refém de feeling. - Você quer “tempo real” mas só tem CPU
CPU pode servir para validação offline, mas real-time geralmente exige GPU. O próprio projeto aponta caminhos para CPU em avaliação offline, não promete real-time em CPU. - Seu caso exige precisão alta, com risco jurídico, médico, financeiro
Você pode testar, mas não colocar em produção sem camadas de segurança e fallback humano. - Você está sem tempo para setup
Se você não consegue reservar 2 horas para montar ambiente e rodar teste controlado, não comece.
FAQ
Roda offline?
Sim. O repositório descreve um modo de avaliação offline que faz streaming de um WAV de entrada e gera um WAV de saída com a mesma duração.
Roda em CPU?
Para avaliação offline, sim, existe orientação para instalar PyTorch CPU e rodar em CPU puro. Para conversa em tempo real, CPU tende a não ser o caminho.
Dá para integrar em app?
Dá, mas o jeito certo é integrar depois que você validar, latência, estabilidade e idioma, senão você vai gastar semanas para descobrir que não atende seu caso. O primeiro passo é teste fechado e relatório de 1 página.
Quais limitações mais comuns?
As mais comuns são: depender de hardware para ter latência boa, sensibilidade a áudio ruim, e performance variar por idioma. Além disso, se a GPU não tiver memória suficiente, você pode precisar usar --cpu-offload.

