
O full-duplex na IA de voz muda a conversa ao permitir que o sistema escute e fale ao mesmo tempo, em vez de esperar o usuário terminar para só então responder. Na prática, isso diminui a sensação de “atendimento por etapas” e aproxima o ritmo de um diálogo humano, com respostas que começam antes do fim da frase, sinais curtos de atenção e correções em tempo real. A diferença aparece menos no que a IA “sabe” e mais em como ela se comporta quando a conversa acelera, hesita ou muda de direção.
Pipeline tradicional, ASR, LLM, TTS, por que dá “pausa robótica”
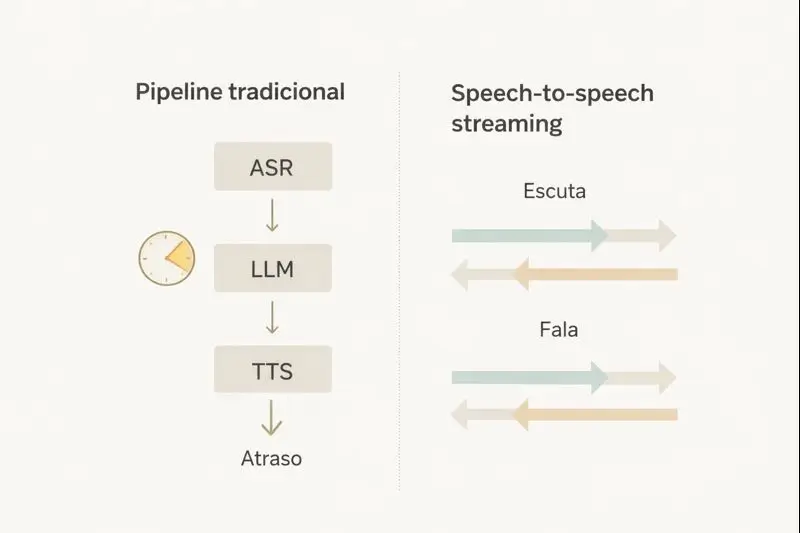
O padrão mais comum ainda é o pipeline em cadeia, no qual o áudio vira texto, o texto vira resposta, e a resposta vira áudio. Em geral, essa cascata passa por ASR para transcrever a fala, LLM para decidir o que dizer, e TTS para sintetizar a voz. O problema não é só a soma dos tempos de cada etapa, mas também o “vai e volta” de rede e a necessidade de detectar com segurança quando o usuário parou de falar, o que pode atrasar o início da resposta.
A “pausa robótica” nasce desse desenho por turnos, porque o sistema tende a esperar um final claro antes de agir. Se o detector de fim de fala for conservador, ele segura alguns centenas de milissegundos extras para evitar cortar o usuário. Se for agressivo, interrompe sem querer e precisa se corrigir, o que também soa artificial. Somado ao tempo de processamento do modelo de linguagem e ao início da síntese, o resultado é uma resposta que chega inteira, tarde, e com pouca fluidez.
Outro efeito colateral do intermediário em texto é que parte do contexto que não cabe bem em palavras se perde no caminho. Entonação, riso, hesitação, suspiro e outros sinais podem mudar o sentido do que foi dito, mas a transcrição costuma “achatá-los” em frases limpas. Quando a IA responde sem levar esses detalhes em conta, a conversa fica correta no conteúdo, porém estranha no timing e no tom. Esse é um dos motivos pelos quais sistemas de fala mais recentes tentam reduzir a dependência de uma conversa rigidamente segmentada.
Na experiência do usuário, a latência vira percepção de competência. Mesmo quando a resposta está certa, atrasos acima de um patamar passam a sensação de lentidão, e o cérebro humano começa a “estranhar” o diálogo. Materiais do setor costumam tratar respostas em faixa de subsegundo como referência para manter naturalidade, enquanto atrasos maiores quebram o ritmo, especialmente em tarefas simples, como confirmar um dado ou dizer “certo, entendi”.
Speech-to-speech streaming, como o modelo pensa e fala junto
A virada do speech-to-speech streaming é tratar o diálogo como geração de fala para fala, em fluxo contínuo, em vez de “áudio para texto para áudio”. Em modelos full-duplex, a entrada chega em pedaços curtos, e a saída também pode começar em pedaços curtos, com a conversa acontecendo em paralelo. No caso do Moshi, a proposta é modelar simultaneamente os fluxos de fala do usuário e do sistema, o que permite lidar melhor com sobreposição de vozes, interjeições e mudanças rápidas de turno, sem depender de cortes rígidos.
Um ponto relevante nessa abordagem é que “pensar” e “falar” deixam de ser blocos separados e passam a ser coordenados no tempo. Em vez de aguardar uma resposta completa para só então sintetizar, o sistema pode iniciar uma fala curta, ajustar o caminho enquanto ouve mais, e completar a ideia conforme a intenção do usuário fica clara. O artigo técnico do Moshi descreve metas de latência na casa de centenas de milissegundos, o que ajuda a explicar por que a resposta pode parecer mais imediata quando comparada a cadeias tradicionais.

Interrupções, turn-taking e backchannels entram aqui como diferença de “comportamento”, não só de velocidade. Interromper com educação, aceitar ser interrompido e retomar o fio é parte do que torna uma conversa eficiente. Backchannels são sinais curtos como “uhum”, “certo”, “entendi”, usados para mostrar acompanhamento sem tomar o turno. Pesquisas recentes vêm tratando esses itens como métricas específicas de qualidade em full-duplex, justamente porque eles afetam a percepção de naturalidade e controle do diálogo.
Na prática de produto, isso melhora UX por três razões. Primeiro, reduz ansiedade, porque o usuário recebe sinais de que foi ouvido antes da resposta final. Segundo, diminui retrabalho, já que a pessoa corrige no meio, e o sistema acompanha sem reiniciar tudo. Terceiro, cria um ritmo mais “cooperativo”, em que a IA administra pausas e confirmações com menos silêncio. Isso não elimina a necessidade de bons conteúdos, mas aumenta a chance de o usuário confiar no fluxo e concluir a tarefa sem repetir frases.
Por que PersonaPlex cita Moshi, e o que isso indica tem a ver com uma tensão que apareceu com os modelos full-duplex: eles soam mais naturais, mas nem sempre oferecem controle fino de voz e papel. A página de pesquisa da NVIDIA PersonaPlex descreve exatamente essa troca, ao comparar cascatas tradicionais, que facilitam personalização, com full-duplex, que melhora dinâmica de conversa, mas pode “prender” o sistema a uma voz e persona fixas. A proposta do PersonaPlex é tentar unir os dois, apoiando-se na arquitetura e nos pesos do Moshi, e adicionando mecanismos para condicionar voz e “papel” por prompts.
Esse movimento indica uma direção provável do mercado: full-duplex como base de fluidez, com camadas por cima para controle e segurança. Em vez de escolher entre naturalidade e personalização, os fornecedores tentam oferecer os dois, ainda que com custos, limites e exigências de dados. Também sugere que a competição vai além de “qual modelo é mais inteligente”, e passa por “qual modelo conversa melhor”, incluindo timing, interrupção, sinais de escuta e consistência de voz, pontos que começam a virar diferencial mensurável.
FAQ:
Qual a diferença de assistente comum? Um assistente comum costuma operar por turnos, esperando o usuário concluir para então responder, geralmente via ASR mais LLM mais TTS. Em full-duplex, o sistema tenta escutar e falar em paralelo, com respostas em fluxo e mais tolerância a interrupções e sobreposição.
Dá para personalizar voz? Em cascatas tradicionais, a troca de voz no TTS é um caminho direto. Em full-duplex, isso depende do modelo e do método de condicionamento. O PersonaPlex apresenta controle de voz e papel como parte central da proposta, justamente para evitar o “engessamento” de voz e persona observado em algumas abordagens full-duplex.
Onde cai a latência? A queda costuma vir de três pontos: menos esperas para “fim de fala”, menos etapas em série e mais geração em streaming, com início de resposta antes da frase terminar. Em modelos como Moshi, a literatura descreve foco em latência de tempo real e em remover a segmentação rígida por turnos, que é uma fonte clássica de atraso percebido.

